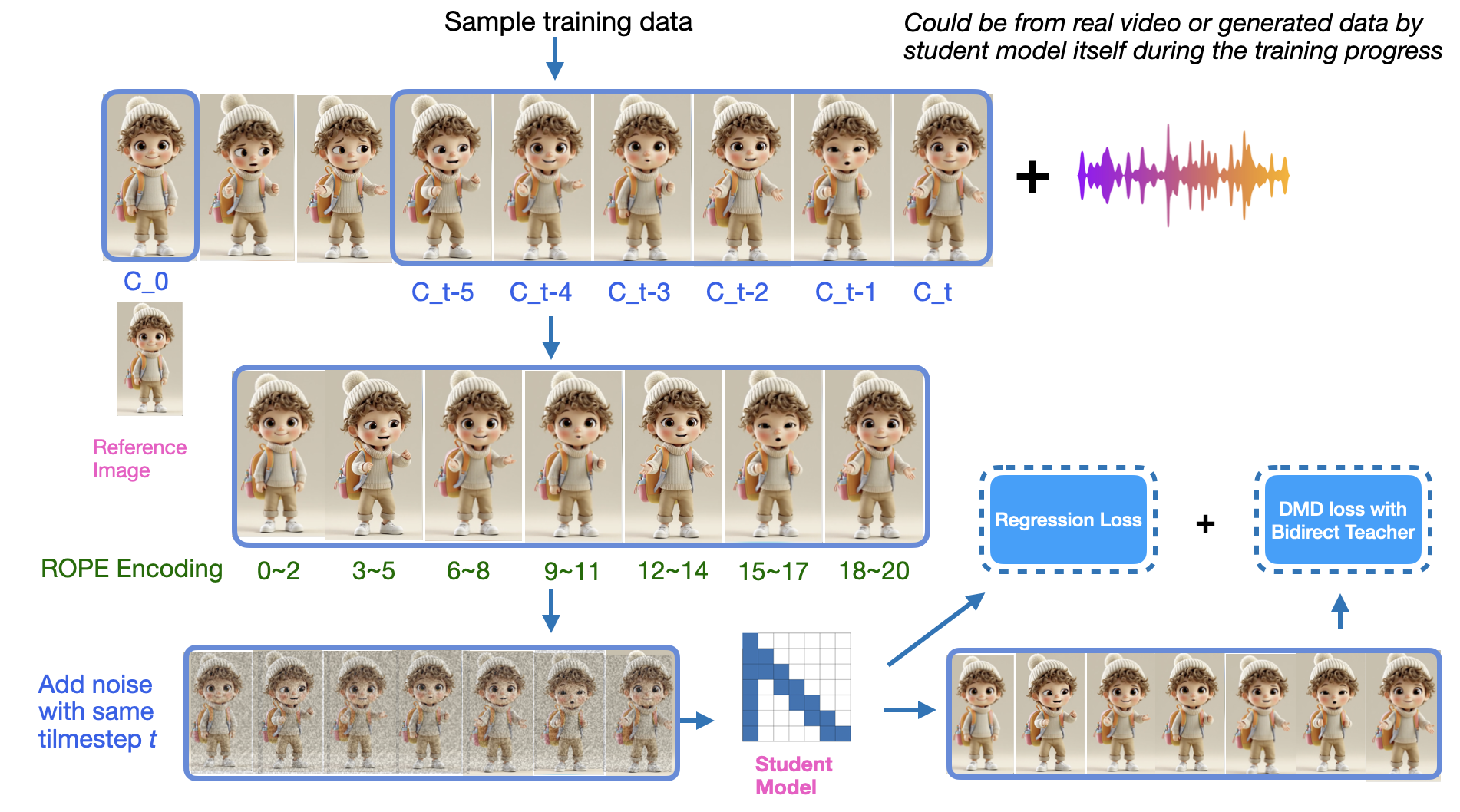
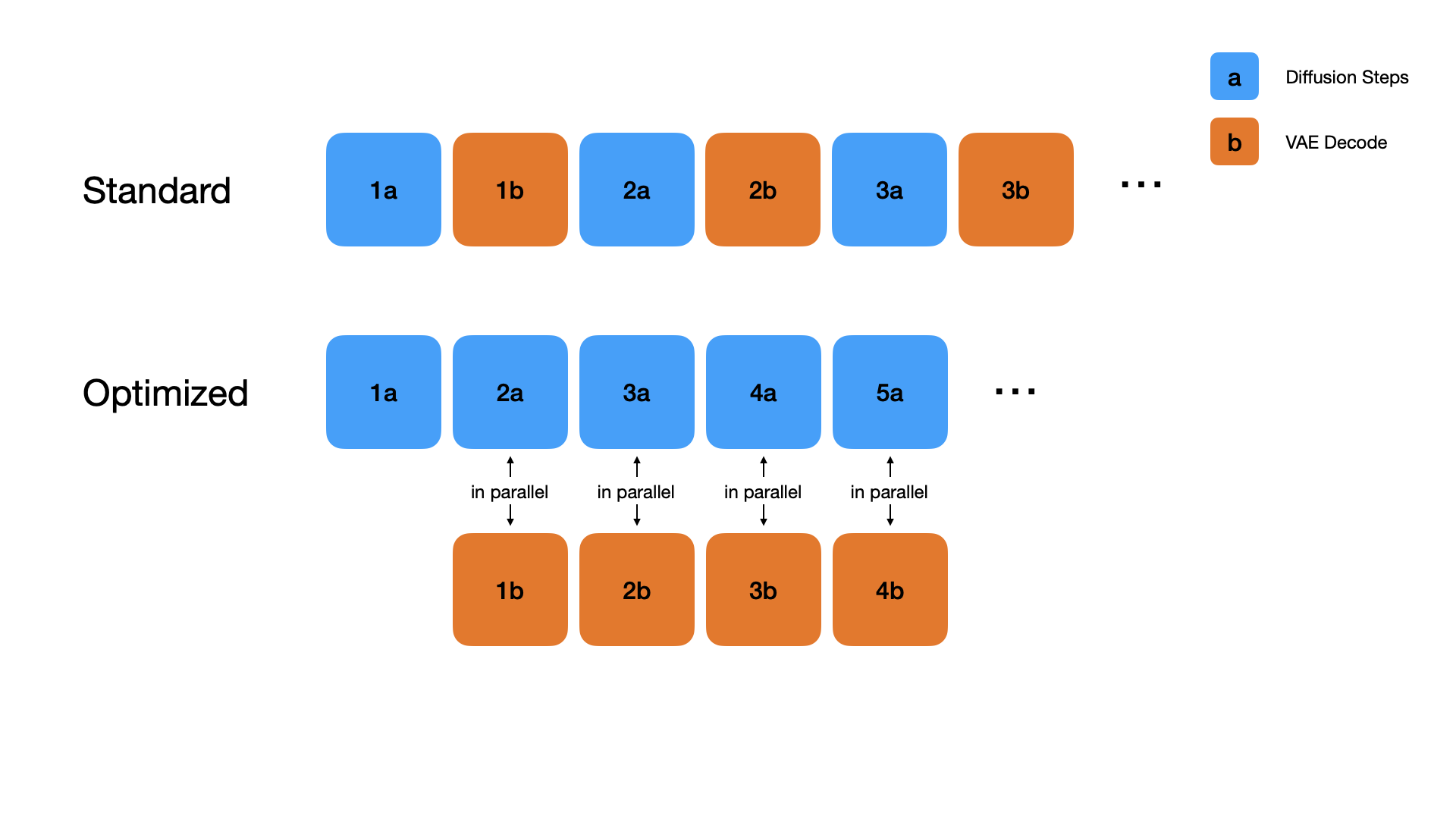
We introduce the first framework to transform a large-scale video foundation model (18B parameters) into a real-time streaming system for audio-driven avatar animation, toggling between speaking and listening modes for infinite turns, enabling immersive and interactive FaceTime experiences from diverse input image styles.
All videos are recorded live. All frames (including `talking` and `listening` modes) are generated in real-time.